Künstliche IntelligenzSeit 2018 entwickelt das Ingenieurbüro Heimann KI-Anwendungen. Künstliche Intelligenz (KI), englisch: Artificial Intelligence (AI) ist ein Bereich der Informatik, der sich mit der Entwicklung von Computern und Systemen befasst, die in der Lage sind, menschenähnliche Intelligenz aufzubringen. Künstliche Intelligenz, ist genau das was der Begriff sagt: Eine Intelligenz, wie wir sie von Menschen und Tieren kennen, künstlich mit Computern nachgebildet. Aber von diesem so einfach formulierten Ziel sind wir derzeit noch ganz weit entfernt. Aber in einigen Teilbereichen der KI gibt es bereits heute sinnvolle Anwendungen. Die wichtigsten Teilbereiche der KI sind:
Weitere Teilbereiche der KI sind: 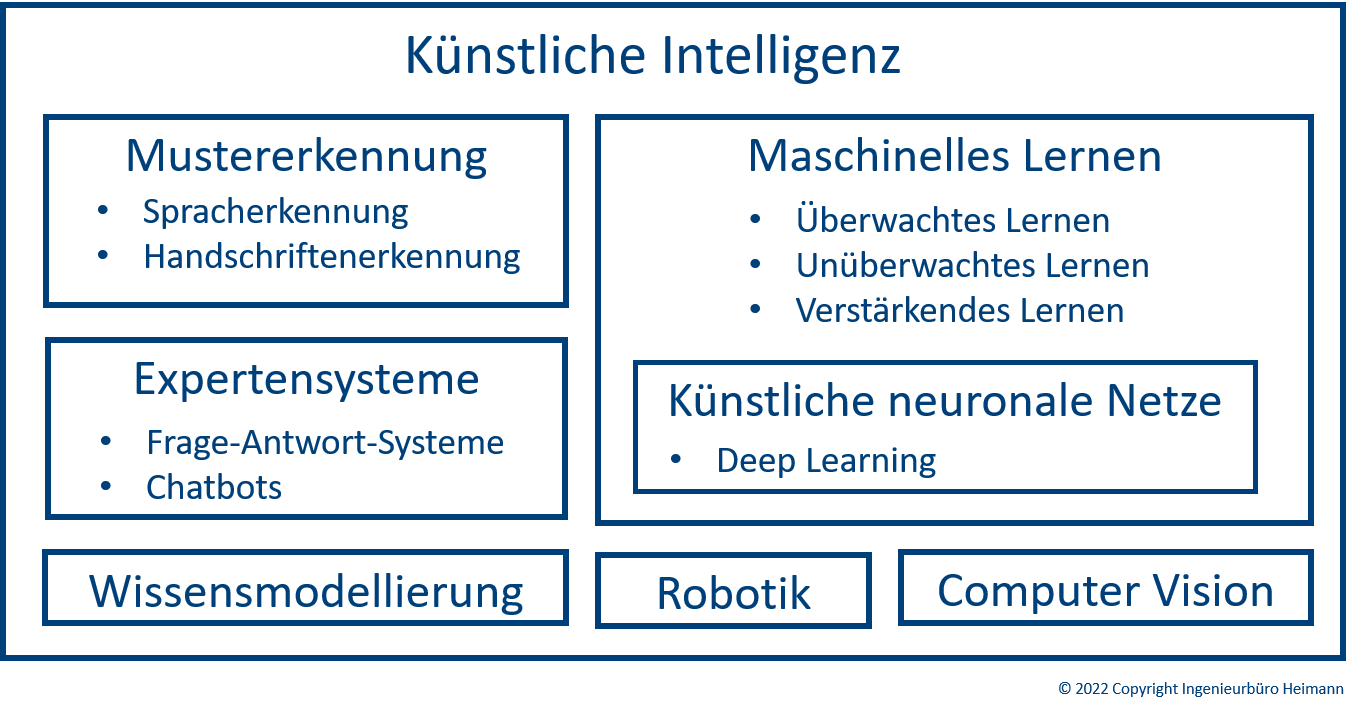
Abbildung 1: Teilbereiche der KI
Stand der TechnikEs gibt verschiedene Fachgebiete der Künstlichen Intelligenz (KI), die unterschiedliche Entwicklungsstadien und Durchbrüche aufweisen. Hier unsere eine grobe Einschätzung: Durchbrüche in der KIBemerkenswerte Durchbrüche der KI hat es in folgenden Bereichen gegeben. Sind also heute schon einsetzbar. Auch für den Mittelstand.
Aktuelle Forschungin der KIEs gibt Fachgebiete der KI, die weiterhin aktiv erforscht werden, um ihre Fähigkeiten zu verbessern und neue Erkenntnisse zu gewinnen. Je nach Anwendungsfall lassen sich hiermit gute Ergebnisse erzielen.
Träume der KIEs gibt auch Fachgebiete der KI, von denen wir heute nur träumen können.
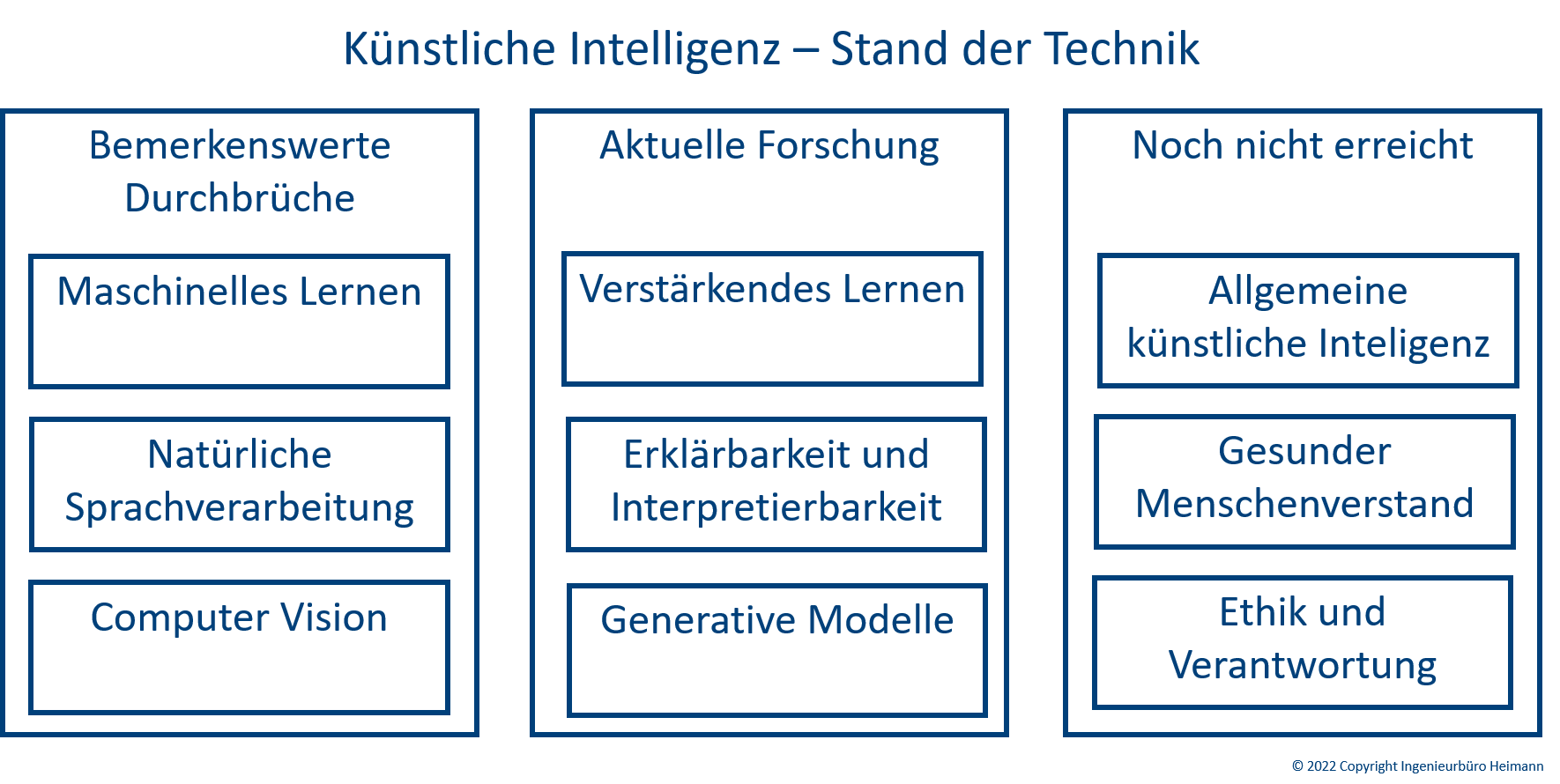
Abbildung 2: Stand der Technik
Maschinelles LernenIntelligenz, so wie es im Allgemeinen bei Menschen verstanden wird, ist derzeit mit Computern nicht möglich. Aber es ist möglich dem Computer beizubringen aus Erfahrungen zu lernen und Aufgaben eigenständig zu erledigen, ohne explizit programmiert zu werden. Es handelt sich um ein Verfahren, bei dem Algorithmen und Modelle entwickelt werden, um Muster und Strukturen in Daten zu erkennen und Vorhersagen oder Entscheidungen zu treffen. Ein zentrales Konzept im maschinellen Lernen ist der Lernprozess, bei dem ein Modell trainiert wird, um aus Daten zu lernen und daraus Schlüsse zu ziehen. Dabei werden in der Regel große Mengen an Trainingsdaten verwendet, um dem Modell verschiedene Beispiele und Muster vorzulegen. Das Modell passt dann seine internen Parameter an, um diese Muster zu erkennen und zu generalisieren. Es gibt verschiedene Arten des maschinellen Lernens, darunter
Beim überwachten Lernen werden dem Modell sowohl Eingabe- als auch Ausgabedaten präsentiert, um es darauf zu trainieren, eine bestimmte Abbildung von Eingabe zu Ausgabe zu erlernen. Beim unüberwachten Lernen hingegen werden dem Modell nur Eingabedaten präsentiert, und es versucht selbstständig, Muster und Strukturen in den Daten zu erkennen. Beim verstärkenden Lernen interagiert das Modell mit einer Umgebung und lernt durch positive oder negative Rückmeldungen, welche Aktionen belohnend oder bestrafend sind. Anwendung von maschinellem LernenMaschinelles Lernen findet in vielen Anwendungsbereichen Anwendung. In der Bilderkennung können beispielsweise Algorithmen trainiert werden, um Objekte oder Gesichter in Bildern zu erkennen. In der Sprachverarbeitung können Modelle verwendet werden, um menschliche Sprache zu verstehen und automatische Übersetzungen oder Sprachassistenten anzubieten. In der Datenvorhersage können Algorithmen genutzt werden, um Trends und Muster in Daten zu identifizieren und Vorhersagen über zukünftige Ereignisse zu treffen. Ein wichtiger Aspekt des maschinellen Lernens ist die Evaluation der Modelle. Es ist wichtig sicherzustellen, dass die trainierten Modelle nicht nur auf den Trainingsdaten gut funktionieren, sondern auch auf neuen, unabhängigen Daten. Hierfür werden typischerweise Testdaten verwendet, um die Leistung und Genauigkeit des Modells zu bewerten. Big DataEine der größten Herausforderungen im maschinellen Lernen ist die Bewältigung großer Datenmengen. Oftmals sind umfangreiche Datenreinigung und -vorverarbeitung erforderlich, um die Qualität der Daten zu verbessern und irrelevante Informationen zu entfernen. Zudem erfordert das Training von Modellen häufig hohe Rechenleistung und spezialisierte Hardware wie Grafikprozessoren (GPUs) oder Tensor Processing Units (TPUs). Trotz der Fortschritte im maschinellen Lernen gibt es auch einige Limitierungen. Einige Modelle können anfällig für Verzerrungen oder Vorurteile in den Daten sein, was zu ungewollten Ergebnissen führen kann. GrenzenZudem kann es schwierig sein, komplexe Zusammenhänge und Kausalitäten in den Daten zu verstehen, da maschinelle Lernmodelle in erster Linie auf statistischen Mustern basieren. FazitInsgesamt bietet maschinelles Lernen ein enormes Potenzial, um komplexe Probleme zu lösen und neue Erkenntnisse aus großen Datenmengen zu gewinnen. Durch die kontinuierliche Weiterentwicklung von Algorithmen, Techniken und Hardware wird erwartet, dass maschinelles Lernen in Zukunft noch weiter an Bedeutung gewinnen wird und vielfältige Anwendungen in verschiedenen Bereichen findet. Deep LearningDeep Learning ist ein Teilbereich des maschinellen Lernens, der sich auf die Verarbeitung und Analyse von komplexen Datenstrukturen konzentriert. Es basiert auf neuronalen Netzwerken, die aus mehreren Schichten von künstlichen Neuronen bestehen und tiefe hierarchische Modelle bilden. Im Gegensatz zu herkömmlichen Machine-Learning-Modellen, die auf manuell entwickelten Merkmalen beruhen, ist Deep Learning in der Lage, automatisch Merkmale aus den Daten zu lernen und komplexe Muster zu erkennen. Die Leistungsfähigkeit von Deep Learning beruht auf der Fähigkeit, hierarchische Darstellungen von Daten zu erlernen. Jede Schicht des neuronalen Netzwerks lernt sukzessive abstraktere und komplexere Merkmale. Die früheren Schichten lernen einfache Merkmale, wie Kanten oder Texturen, während die späteren Schichten komplexere Merkmale oder sogar Konzepte erkennen können. Durch diese Hierarchie ist Deep Learning in der Lage, Daten auf mehreren Abstraktionsebenen zu interpretieren und detaillierte Einblicke zu gewinnen. Ein Schlüsselkonzept im Deep Learning ist das Training des neuronalen Netzwerks. Dabei werden große Mengen an Daten verwendet, um das Modell auf eine spezifische Aufgabe anzupassen. Das Training erfolgt durch die Anpassung der Gewichte und Parameter des Netzwerks, um die Vorhersagegenauigkeit zu verbessern. Dies geschieht mithilfe von Optimierungsalgorithmen wie dem Gradientenabstiegsverfahren, die den Fehler zwischen den vorhergesagten und tatsächlichen Werten minimieren. Deep Learning findet Anwendung in verschiedenen Bereichen, wie beispielsweise der Bild- und Spracherkennung, der Natural Language Processing (NLP), der medizinischen Bildgebung, der autonomen Fahrzeugtechnik und vielen anderen. Durch die Fähigkeit, komplexe Muster zu erkennen und abstrakte Repräsentationen zu erlernen, hat Deep Learning bahnbrechende Fortschritte in diesen Bereichen ermöglicht. Um Deep Learning effektiv einzusetzen, sind große Datenmengen erforderlich, da das Modell ausreichend Beispiele benötigt, um Muster zu erkennen und zu generalisieren. Zudem ist eine hohe Rechenleistung erforderlich, um die komplexen Berechnungen durchzuführen. Daher werden spezielle Hardware wie Grafikprozessoren (GPUs) oder Tensor Processing Units (TPUs) verwendet, um die Trainingseffizienz zu verbessern. Trotz der beeindruckenden Leistungsfähigkeit von Deep Learning gibt es auch Herausforderungen. Die Interpretierbarkeit von Deep-Learning-Modellen ist oft begrenzt, da sie als "Black Box" betrachtet werden. Es kann schwierig sein, zu verstehen, wie das Modell zu seinen Vorhersagen gelangt ist. Zudem sind große Datenmengen erforderlich, um genaue und zuverlässige Modelle zu trainieren, was den Zugang zu ausreichenden Datenquellen erschweren kann. Erfolgsfaktoren in der KIDie Entwicklung von KI-Software erfordert eine systematische Herangehensweise und die Berücksichtigung bestimmter Erfolgsfaktoren. Erfolgsfaktor 1: Datenqualität und -quantitätDie Qualität und Quantität der Daten sind von entscheidender Bedeutung für die Entwicklung von KI-Software. Je mehr qualitativ hochwertige Daten verfügbar sind, desto besser kann das KI-Modell trainiert werden. Es ist wichtig, ausreichend Daten für verschiedene Szenarien und Anwendungsfälle zu haben, um eine robuste und generalisierte Lösung zu entwickeln. Erfolgsfaktor 2: Fachwissen und DomänenkenntnisseDas Fachwissen und die Domänenkenntnisse der Entwickler spielen eine entscheidende Rolle bei der Entwicklung von KI-Software. Ein tiefes Verständnis der zugrunde liegenden Konzepte und Algorithmen ist erforderlich, um die richtigen Entscheidungen bei der Modellauswahl, den Parametereinstellungen und der Evaluierung der Ergebnisse zu treffen. Domainexperten können auch dabei helfen, relevante Merkmale zu identifizieren und das Modell an die spezifischen Anforderungen der Anwendung anzupassen. Erfolgsfaktor 3: Auswahl der richtigen Algorithmen und FrameworksDie Auswahl der geeigneten KI-Algorithmen und -Frameworks ist ein weiterer wichtiger Erfolgsfaktor. Es stehen eine Vielzahl von Algorithmen und Frameworks zur Verfügung, die unterschiedliche Vor- und Nachteile haben. Die Wahl des richtigen Ansatzes hängt von den Anforderungen des Projekts, den verfügbaren Daten und der zugrunde liegenden Problemstellung ab. Es ist wichtig, die verschiedenen Optionen sorgfältig zu evaluieren und das am besten geeignete Modell für die spezifische Aufgabe auszuwählen. Erfolgsfaktor 4: Kontinuierliches Modelltraining und -optimierungDie Entwicklung von KI-Software endet nicht mit dem Training eines Modells. Es ist wichtig, das Modell kontinuierlich zu trainieren und zu optimieren, um die Leistung zu verbessern. Neue Daten können gesammelt und in den Trainingsprozess einbezogen werden, um das Modell an neue Bedingungen anzupassen und die Genauigkeit zu steigern. Auch das Fine-Tuning von Parametern und die Optimierung der Hyperparameter können dazu beitragen, die Leistung des Modells zu verbessern. Erfolgsfaktor 5: Effektive Validierung und EvaluierungEine effektive Validierung und Evaluierung des entwickelten KI-Modells ist von entscheidender Bedeutung, um sicherzustellen, dass es die gewünschten Ergebnisse liefert. Dies umfasst die Verwendung geeigneter Metriken zur Leistungsbewertung, das Testen des Modells mit neuen Datensätzen und die Überprüfung, ob das Modell die gewünschten Ziele erreicht. Eine gründliche Validierung und Evaluierung ermöglicht es, mögliche Schwachstellen zu identifizieren und das Modell entsprechend zu verbessern. |
KI AnwendungsfälleBranchen-KompetenzStellenangeboteFachkraft für Alternativ-Elektronikbauteilsuche (m/w/d)17. Dezember 2025, ÜberlingenPartner Company Material Manager - Wirtschaftsingenieur (m/w/d)17. Dezember 2025, DonauwörthIngenieur (w/m/d) für Systemtests17. Dezember 2025, UlmFPGA Entwickler (m/w/d)17. Dezember 2025, TaufkirchenC# / .NET Softwareentwickler (m/w/d)17. Dezember 2025, FriedrichshafenAktuellesDas Crowdstrike-Fiasko --- Ursachenforschung und erste Lehren24. Juli 2024Ein fehlerhaftes Update für Crowdstrikes Agent-Software führte dazu, dass weltweit rund 8,5 Millionen Windows-PCs abstürzten – viele davon in Produktivumgebungen in Firmen. Der Fehler war so hartnäckig, dass ein Neustart nicht möglich war: Windows fraß sich immer wieder an derselben Stelle fest. Das Problem gilt vielen bereits als der größte Ausfall der IT-Geschichte. Betrugserkennung durch Künstliche Inteligenz8. Juli 2024In einer Zeit, in der digitale Betrugsfälle immer raffinierter und schwerer zu erkennen werden, bietet die Künstliche Intelligenz (KI) innovative Lösungen zur Betrugserkennung und -prävention. Erfahren Sie, wie KI-Systeme durch maschinelles Lernen Muster und Anomalien in Daten erkennen, welche Vorteile sie bieten und wie sie in verschiedenen Branchen erfolgreich eingesetzt werden. Entdecken Sie die Herausforderungen und die Zukunftsaussichten der KI-gestützten Betrugserkennung in unserem umfassenden Artikel. Künstliche Intelligenz im Mittelstand1. Juli 2024Der Mittelstand kann Künstliche Intelligenz (KI) in vielen Bereichen einsetzen, um Effizienz zu steigern, Kosten zu senken und die Wettbewerbsfähigkeit zu erhöhen. Hier sind 10 Einsatzgebiete, in denen der Mittelstand KI aktuell nutzen kann: Vorsprung durch Klassifikationen mit Künstlicher Inteligenz12. September 2023Künstliche Intelligenz (KI) ist in vielen Bereichen des Lebens allgegenwärtig geworden, von der Unterhaltung bis zur Medizin. Eine der wichtigsten Anwendungen von KI ist die Klassifikation von Daten. Klassifikation bedeutet, dass Daten in verschiedene Kategorien eingeteilt werden. Dies kann zum Beispiel für die Erkennung von Objekten in Bildern, die Textanalyse oder die Vorhersage von Ereignissen verwendet werden. KI-basierte Klassifikationen bieten Unternehmen zahlreiche Vorteile. Sie können dazu beitragen, die Effizienz zu steigern, die Qualität zu verbessern und neue Möglichkeiten zu erschließen. Mit dem Ingeneiurbüro Heimann können auch mittelständige Unternehmen diese Technologie gewinnbringend nutzen. Bei Cybersicherheit geht es nicht um Computer – sondern um unsere tägliche Sicherheit11. September 2023Cyberangriffe können für Unternehmen existenzbedrohend sein und werden oft unterschätzt. Cybersicherheit sollte deswegen selbstverständlich sein. |






