Klassifikationen mit künstlicher IntelligenzDaten zu klassifizieren ist ein Anwendungsfall von Künstlicher Intelligenz. Bei der Klassifikation geht es darum Daten verschiedenen Klassen oder Kategorien zuzuordnen. Zum Beispiel:
Wie wird klassifiziert?Die meisten Klassifikationen werden nicht von Grund auf neu entwickelt, da für anspruchsvolle Klassifikationen umfangreiche vorklassifizierte Datensätze vorhanden sein müssen. Deshalb werden für die meisten Klassifikationen vorhandene Datenmodelle genutzt. Die Hauptaufgabe besteht dann darin im Internet ein möglichst passendes Klassifizierungsmodel zu finden. Bewährte und stabile Datenmodelle gibt es zum Beispiel in folgenden Anwendungsbereichen:
FunktionsweiseBei einer Klassifizierung geht es - vereinfacht gesprochen - aus einer großen Datenmenge diejenigen Datensätze zu finden, deren Merkmale relativ "dicht" beieinander liegen. 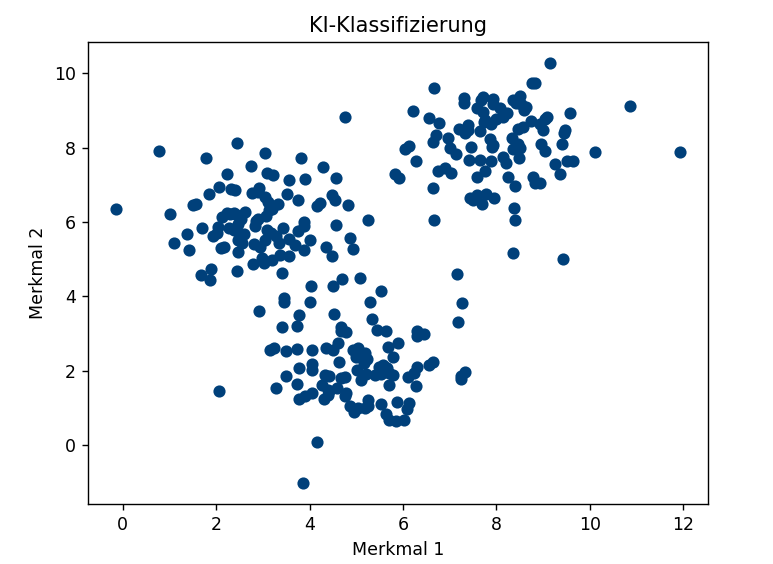
Abbildung 1: Unklassifizierte Daten
Das KI-System kann, nach entsprechendem Training, die Datensätze bestimmten Klassen oder Kategorien zuordnen. 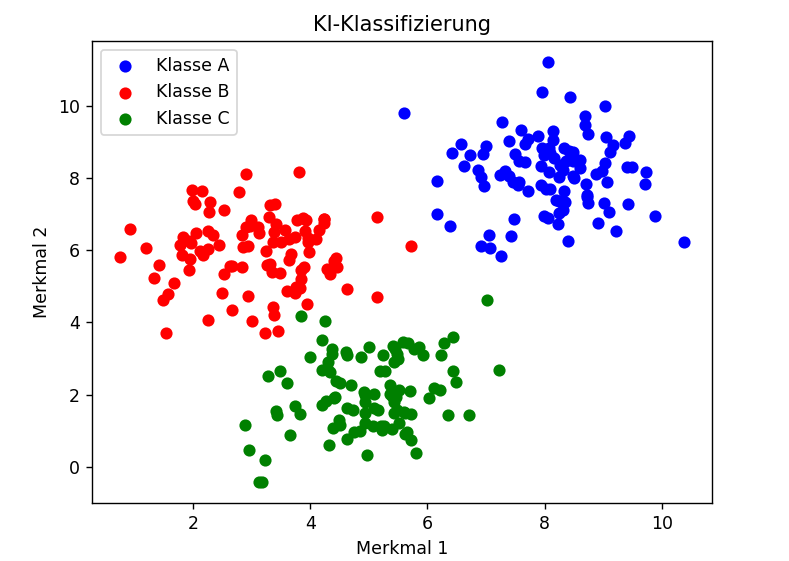
Abbildung 2: Klassifizierte Daten
Durch die Auswahl geeigneter Merkmale, kann es so relativ einfach sein, die gesuchten Daten zu finden. 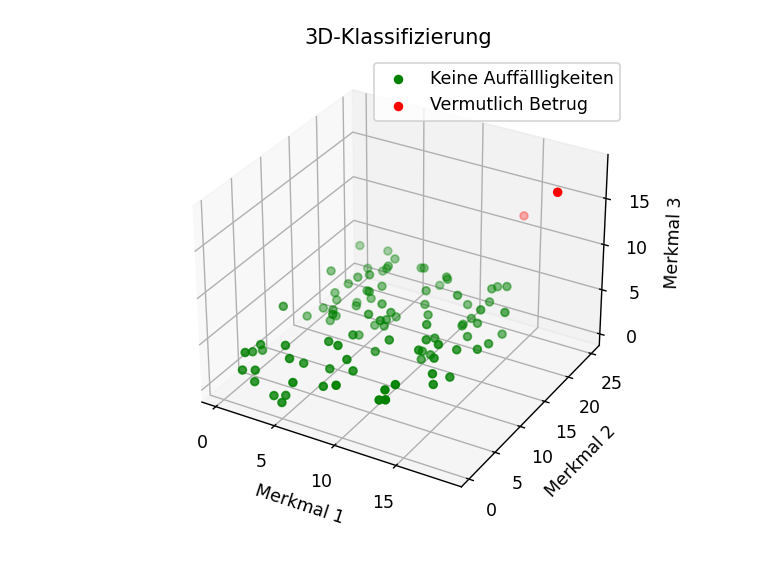
Abbildung 3: Verdachtsmomente erkennen
Erfolgsfaktoren für KI-KlassifikationenUm KI-Klassifikationen erfolgreich umzusetzen und aussagekräftige Ergebnisse zu erzielen, spielen verschiedene Erfolgsfaktoren eine Rolle: Erfolgsfaktor 1: DatenqualitätEine hohe Datenqualität ist entscheidend für präzise Klassifikationen. Saubere, gut strukturierte und ausreichend umfangreiche Daten bilden die Grundlage für zuverlässige Modelle. Erfolgsfaktor 2: Auswahl des richtigen AlgorithmusEs gibt verschiedene Klassifikationsalgorithmen, die je nach Datensatz und Problemstellung unterschiedliche Ergebnisse liefern können. Die Auswahl des richtigen Algorithmus ist daher von großer Bedeutung. Erfolgsfaktor 3: Feature EngineeringEine sorgfältige Auswahl und Aufbereitung der Merkmale (Features) kann die Leistung der Klassifikationsmodelle verbessern. Das Identifizieren relevanter Features und das Entfernen irrelevanter oder redundanter Informationen sind wichtige Schritte. Erfolgsfaktor 4: TrainingsdatenDie Qualität und Repräsentativität der Trainingsdaten beeinflussen die Leistung der Klassifikationsmodelle. Ausreichend große und vielfältige Trainingsdatensätze sind notwendig, um ein Modell mit hoher Generalisierungsfähigkeit zu erstellen. Erfolgsfaktor 5: Evaluierung und ValidierungEine regelmäßige Evaluierung und Validierung der Klassifikationsmodelle sind wichtig, um deren Leistungsfähigkeit zu überprüfen. Dies umfasst die Verwendung von Testdaten, Kreuzvalidierung und anderen Evaluierungsmethoden. Best Practices für KI-KlassifikationenUm das volle Potenzial von KI-Klassifikationen auszuschöpfen, können folgende Best Practices berücksichtigt werden: Best Practices 1: DatenverständnisEine gründliche Analyse und das Verständnis der Daten sind entscheidend, um geeignete Klassifikationsmodelle zu entwickeln. Dazu ist das Erforschen von Daten, identifizieren von Mustern und Zusammenhängen, um die Grundlage für die Klassifikation zu legen. Best Practices 2: Feature-AuswahlMit einem Feature werden in der KI die Daten bezeichnet, die als Eingabe verwendet werden. Hierbei gilt es diejenigen Merkmale zu identifizieren, die den größten Einfluss auf die Klassifikation haben. Techniken wie Feature Selection kommen hier zum Einsatz, um die relevantesten Features zu extrahieren und die Dimensionalität der Daten zu reduzieren. Best Practices 3: Hyperparameter-Optimierung:Hyperparameter sind Einstellungen mit denen einzelne Algorithmen an das jeweilige Problem angepasst werden können. Häufig hilft nur Experimentieren und Erfahrung um die verschiedenen Hyperparameter-Einstellungen, um die Leistung des Klassifikationsmodelles zu verbessern. Grid Search oder Random Search können helfen um die optimalen Hyperparameter zu finden. Best Practices 4: Modellinterpretation:Es hilft, wenn man versteht, wie das Klassifikationsmodell Entscheidungen trifft. Techniken wie Feature Importance, können helfen um die einzelnen Merkmale zur Klassifikation zu bewerten und die Interpretierbarkeit des Modells zu verbessern. Best Practices 5: Kontinuierliches Lernen und Aktualisierung:Ein einmal entwickeltes Klassifikationsmodell muss kontinuierlich überwacht und aktualisiert werden. Insbesondere dann, wenn neuere Daten zur Verfügung stehen. Nur so kann eine hohe Aktualität und Genauigkeit zu gewährleistet werden. |
KI AnwendungsfälleStellenangeboteFachkraft für Alternativ-Elektronikbauteilsuche (m/w/d)17. Dezember 2025, ÜberlingenPartner Company Material Manager - Wirtschaftsingenieur (m/w/d)17. Dezember 2025, DonauwörthIngenieur (w/m/d) für Systemtests17. Dezember 2025, UlmFPGA Entwickler (m/w/d)17. Dezember 2025, TaufkirchenC# / .NET Softwareentwickler (m/w/d)17. Dezember 2025, FriedrichshafenBranchen-KompetenzAktuellesDas Crowdstrike-Fiasko --- Ursachenforschung und erste Lehren24. Juli 2024Ein fehlerhaftes Update für Crowdstrikes Agent-Software führte dazu, dass weltweit rund 8,5 Millionen Windows-PCs abstürzten – viele davon in Produktivumgebungen in Firmen. Der Fehler war so hartnäckig, dass ein Neustart nicht möglich war: Windows fraß sich immer wieder an derselben Stelle fest. Das Problem gilt vielen bereits als der größte Ausfall der IT-Geschichte. Betrugserkennung durch Künstliche Inteligenz8. Juli 2024In einer Zeit, in der digitale Betrugsfälle immer raffinierter und schwerer zu erkennen werden, bietet die Künstliche Intelligenz (KI) innovative Lösungen zur Betrugserkennung und -prävention. Erfahren Sie, wie KI-Systeme durch maschinelles Lernen Muster und Anomalien in Daten erkennen, welche Vorteile sie bieten und wie sie in verschiedenen Branchen erfolgreich eingesetzt werden. Entdecken Sie die Herausforderungen und die Zukunftsaussichten der KI-gestützten Betrugserkennung in unserem umfassenden Artikel. Künstliche Intelligenz im Mittelstand1. Juli 2024Der Mittelstand kann Künstliche Intelligenz (KI) in vielen Bereichen einsetzen, um Effizienz zu steigern, Kosten zu senken und die Wettbewerbsfähigkeit zu erhöhen. Hier sind 10 Einsatzgebiete, in denen der Mittelstand KI aktuell nutzen kann: Vorsprung durch Klassifikationen mit Künstlicher Inteligenz12. September 2023Künstliche Intelligenz (KI) ist in vielen Bereichen des Lebens allgegenwärtig geworden, von der Unterhaltung bis zur Medizin. Eine der wichtigsten Anwendungen von KI ist die Klassifikation von Daten. Klassifikation bedeutet, dass Daten in verschiedene Kategorien eingeteilt werden. Dies kann zum Beispiel für die Erkennung von Objekten in Bildern, die Textanalyse oder die Vorhersage von Ereignissen verwendet werden. KI-basierte Klassifikationen bieten Unternehmen zahlreiche Vorteile. Sie können dazu beitragen, die Effizienz zu steigern, die Qualität zu verbessern und neue Möglichkeiten zu erschließen. Mit dem Ingeneiurbüro Heimann können auch mittelständige Unternehmen diese Technologie gewinnbringend nutzen. Bei Cybersicherheit geht es nicht um Computer – sondern um unsere tägliche Sicherheit11. September 2023Cyberangriffe können für Unternehmen existenzbedrohend sein und werden oft unterschätzt. Cybersicherheit sollte deswegen selbstverständlich sein. |






